第1章 序論:シリコンの限界とAI特化型計算の必然性
人工知能(AI)、特に大規模言語モデル(LLM)と生成AIの急速な発展は、従来の計算機アーキテクチャに突きつけられた「挑戦状」と言える。ムーアの法則の鈍化が叫ばれる一方で、AIモデルのパラメータ数は指数関数的に増加し続けており、計算能力の供給と需要の間には巨大な乖離が生じている。このギャップを埋めるために、汎用的な計算処理装置(CPU)や、グラフィックス処理から転用されたGPU(Graphics Processing Unit)を超えた、AIワークロードに完全に特化したシリコンの必要性が叫ばれてきた。Googleが開発したTPU(Tensor Processing Unit)と、それを制御するためのコンパイラベースのフレームワークJAXは、この歴史的な要請に対する一つの回答であり、今後のAI開発における事実上の「標準スタック」としての地位を確立しつつある。
本レポートは、TPUハードウェアのアーキテクチャ的優位性、JAXの数理的・実装的哲学、そしてこれらが融合することで実現される大規模分散学習のメカニズムについて、包括的かつ詳細に分析を行うものである。
1.1 フォン・ノイマン・ボトルネックの終焉
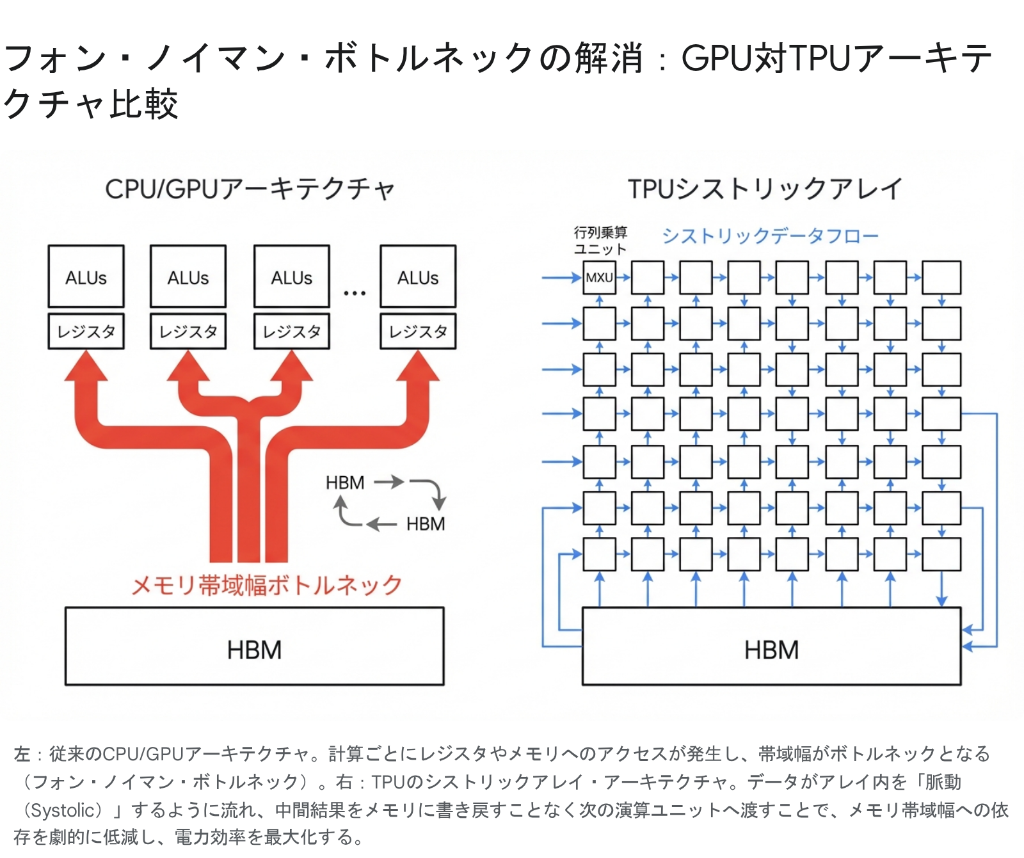
現代のAI計算、特にディープラーニングのトレーニングと推論における最大の障壁は、演算速度そのものではなく、データの移動にある。従来のCPUやGPUは「フォン・ノイマン型アーキテクチャ」に基づいて設計されており、演算装置(ALU)とメモリが分離されている。計算を行うたびに、データはメモリからレジスタへ読み込まれ、演算され、結果が書き戻される。このプロセスは、複雑な分岐予測やキャッシュ管理を必要とする汎用アプリケーションには適しているが、単純な行列積和演算(Matrix Multiply-Accumulate)を数千億回繰り返すAIワークロードにおいては、甚大な非効率を生む 。
いわゆる「メモリの壁(Memory Wall)」問題である。演算器の速度向上に対し、メモリ帯域幅の向上は追いついておらず、プロセッサはデータの到着を待つアイドル状態(ストール)に陥りやすい。AIモデルが大規模化するにつれ、このデータ移動にかかるエネルギーとレイテンシがシステム全体のボトルネックとなり、スケーリングの限界を規定する要因となっている。
1.2 Googleの回答:ドメイン特化型アーキテクチャ(DSA)
Googleはこの問題に対し、汎用性を犠牲にして特定のドメイン(ここでは行列演算)に特化する「ドメイン特化型アーキテクチャ(Domain Specific Architecture: DSA)」のアプローチを採用した。TPUは、ニューラルネットワークの計算の核心である行列演算において、メモリ配管(Data Plumbing)のオーバーヘッドを極限まで排除するように設計されている 。
その中心となる技術が「シストリックアレイ(Systolic Array)」である。これは、心臓が血液を送り出す「収縮(Systole)」の動作にちなんで名付けられたアーキテクチャであり、データがプロセッサ内を波のように伝播する仕組みを指す。この設計思想の違いこそが、TPUがGPUと比較して高い電力効率(Performance per Watt)を実現する根本的な理由である。
第2章 TPUハードウェア・アーキテクチャの進化と詳細分析
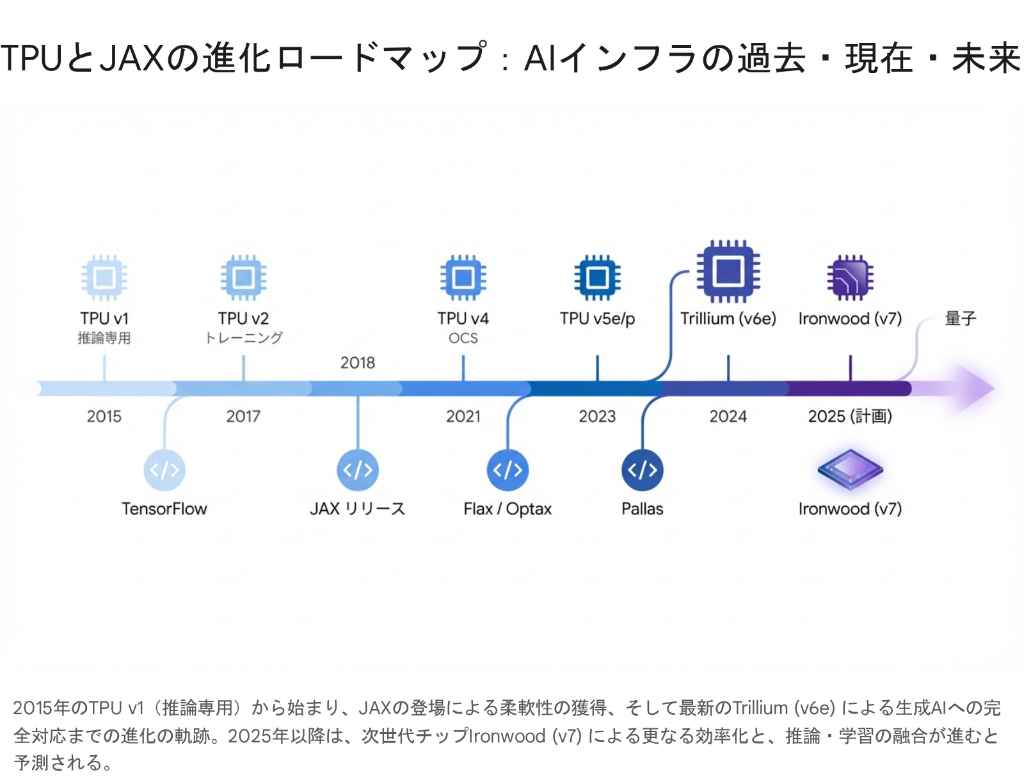
TPUは2015年の登場以来、急速な進化を遂げてきた。初期の推論専用チップから、現在では世界最大級のスーパーコンピュータを構成する基盤技術へと変貌している。本章では、各世代の技術的特異点と、最新のTrillium(TPU v6e)に至るまでの系譜を詳細に分析する。
2.1 黎明期:推論特化から学習への跳躍 (v1 - v3)
TPU v1: 推論の効率化への挑戦
2015年に配備された初代TPUは、Googleのデータセンターにおける推論ワークロード(Google検索、翻訳、YouTubeなど)の急増に対処するために設計された 。
- アーキテクチャ: 256×256の8ビット整数(INT8)乗算器からなるシストリックアレイを搭載し、当時のCPUやGPUと比較して15〜30倍の推論性能と、30〜80倍の電力効率を実現した。
- 制約: トレーニング機能を持たず、ホストCPUからのCISC命令によって駆動されるコプロセッサ的な位置づけであった。メモリにはDDR3を使用し、帯域幅は34 GB/sに留まっていた 。
TPU v2 & v3: 学習への対応と液冷システムの導入
2017年のTPU v2、2018年のv3の登場は、TPUを「推論チップ」から「学習プラットフォーム」へと変貌させた。
- 浮動小数点演算の導入: トレーニングに不可欠な浮動小数点演算をサポートするため、Googleは「bfloat16(Brain Floating Point Format)」という独自のフォーマットを採用した。これは FP32 と同じ 8 ビットの指数部を持ちながら、仮数部を 7 ビットに削減することで、メモリ帯域を節約しつつ、学習に必要なダイナミックレンジを確保するものである 。
- HBMとインターコネクト: 高帯域幅メモリ(HBM)が採用され、チップ間を直接接続する独自のインターコネクト(ICI)により、256チップ以上の大規模クラスタ(Pod)構成が可能となった。TPU v3では、チップの発熱に対処するために液冷システムが導入され、Podあたりの性能は100ペタフロップスを超えた 。
2.2 成熟期:光回路スイッチングとスケーラビリティの革新 (v4)
2021年に発表されたTPU v4は、インターコネクト技術におけるパラダイムシフトをもたらした。
- 光回路スイッチ (Optical Circuit Switches: OCS): 従来の電気的なパケットスイッチングに代わり、MEMSミラーを用いた光回路スイッチが導入された。これにより、データセンター内の接続トポロジーを物理層で動的に再構成することが可能となった 。
- 3Dトーラス・トポロジー: チップ同士は6方向の隣接チップと直結され、3次元トーラス構造を形成する。OCSにより、障害が発生したチップを物理的にバイパスしたり、ワークロードに応じてトポロジーを「Twisted Torus(ねじれたトーラス)」に変更することで、通信のホップ数を削減し、レイテンシを最小化している 。
- 性能: 1つのPodは4,096チップで構成され、最大1.1エクサフロップスの演算性能を提供する。これは、同世代のNVIDIA A100 GPUと比較して、大規模モデルの学習において1.2〜1.7倍の性能と、大幅な電力効率の向上を実現している 。
2.3 分化と特化:v5eとv5p
第5世代において、GoogleはTPUのラインナップを用途別に分化させる戦略をとった。
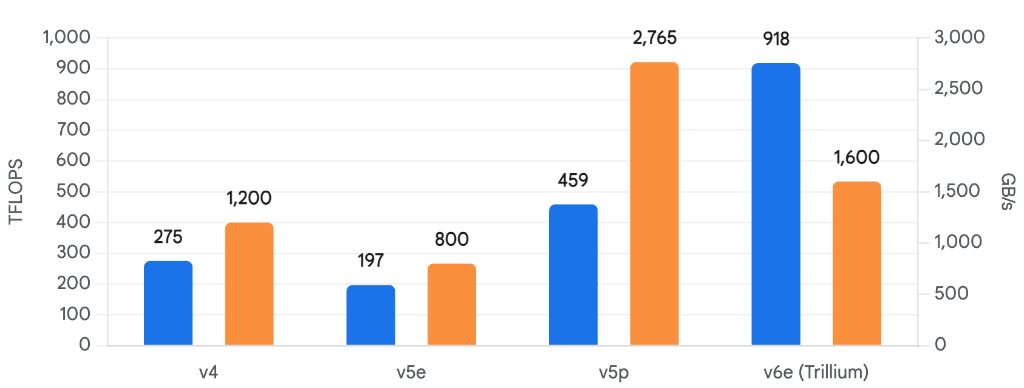
- TPU v5e (Efficient): コスト効率と推論性能を重視したモデル。v4と比較して、ドルあたりの推論スループットは2.5倍に向上している。Transformerモデルや推奨システムの推論、および中規模の学習に適しており、1チップあたりのコストを抑えつつ高いスケーラビリティを提供する 。
- TPU v5p (Performance): 大規模基盤モデル(Foundation Models)の学習に特化したハイエンドモデル。v4と比較してFLOPSは2倍、メモリ帯域は3倍に強化され、最大8,960チップのPod構成をサポートする。これにより、数兆パラメータ級のモデル学習時間を大幅に短縮可能とした 。
2.4 最新世代:Trillium (v6e) の衝撃
2024年、Googleは第6世代となる「Trillium (v6e)」を発表し、一般提供を開始した。これは、生成AI時代の要求に完全に応えるために設計された、現時点で最も強力なTPUである。
- マトリックス演算ユニット (MXU) の巨大化: 特筆すべきは、MXUのサイズが従来の128×128から256×256へと拡張された点である。これにより、クロックあたりの演算数は4倍に増加し、ピーク演算性能(bf16)は1チップあたり918 TFLOPSに達した。これはv5eの約4.7倍の性能向上である 。
- メモリと帯域の倍増: HBM容量は32GB、帯域幅は1,600 GB/sへと倍増した。また、チップ間接続(ICI)帯域も800 GB/sに強化され、大規模分散学習における通信ボトルネックをさらに押し広げている 。
- SparseCoreの進化: 埋め込み層(Embedding)やGNN(グラフニューラルネットワーク)などの疎行列演算を加速する専用コア「SparseCore」の第3世代が搭載されている。これにより、TransformerのAttention計算だけでなく、検索やレコメンデーションといった広範なワークロードの高速化を実現している 。
第3章 JAX:コンパイラ駆動型ソフトウェアの哲学
ハードウェアがいかに高性能であっても、それを制御するソフトウェアが非効率であれば意味がない。PyTorchやTensorFlowといった従来のフレームワークが「命令型(Imperative)」であり、柔軟性が高い反面、超大規模な並列計算における最適化に限界を抱えていたのに対し、Googleは「コンパイラファースト」のアプローチをとるJAXを開発した。
3.1 「Just Another XLA」としてのJAX
JAXという名称は「Just Another XLA」に由来するとも言われる通り、その本質はXLA(Accelerated Linear Algebra)コンパイラへのフロントエンドである 。PythonとNumPyの親さりげない構文を提供しつつ、その裏側では計算全体を中間表現(HLO: High Level Optimizer IR)に変換し、TPUやGPUのネイティブコードへとコンパイルする。
純粋関数型プログラミングの強制
JAXの設計思想の核にあるのは、厳格な関数型プログラミング(Functional Programming)の採用である。
- 純粋関数 (Pure Functions): 関数は副作用(Side Effects)を持ってはならない。同じ入力に対しては常に同じ出力を返し、グローバル変数や外部の状態に依存してはならない 。
- イミュータビリティ (Immutability): 配列は変更不可能である。
x = 1のようなインプレース更新は禁止されており、x.at.set(1)のように新しい配列を生成する記法が求められる 。
これらは一見、開発者に対する制約のように思えるが、実はコンパイラに対する「保証」である。副作用がないことが保証されているため、XLAは計算グラフの順序を自由に入れ替え、融合(Fusion)し、並列化することができる。PyTorchのような動的グラフ(Define-by-Run)では、ユーザーがいつ副作用を起こすか予測できないため、こうした大胆な最適化は困難である。
3.2 JAXの「3つの魔法」:jit, grad, vmap
JAXの機能は、Python関数を別の関数に変換する(Transform)3つの主要なAPIに集約される 。
jax.jit(Just-In-Time Compilation):
Python関数をXLAでコンパイルし、高速化する。初回の呼び出し時にトレーシングが行われ、計算グラフが構築・コンパイルされる。2回目以降はキャッシュされた機械語が実行されるため、Pythonのオーバーヘッドが完全に排除される。jax.grad(Automatic Differentiation):
関数の勾配(微分)を計算する新しい関数を生成する。JAXの自動微分は非常に柔軟で、grad(grad(grad(f)))のように高階微分を容易に記述できる。これは物理シミュレーションやメタ学習において強力な武器となる。jax.vmap(Auto-Vectorization):
単一のデータポイント用に書かれた関数を、自動的にバッチ処理(ベクトル化)用に変換する。forループを使ってバッチ処理を書く必要がなくなり、XLAが並列処理に最適なベクトル命令を生成する 。
3.3 乱数生成のパラダイムシフト
従来のフレームワーク(PyTorchなど)では、乱数生成器(RNG)はグローバルな状態として管理される。しかし、JAXでは純粋関数性を維持するため、RNGの状態も明示的に引数として受け渡し、更新されたキーを返す必要がある。
# PyTorch style (Implicit state)
# torch.manual_seed(0)
# r = torch.rand(1)
# JAX style (Explicit state)
key = jax.random.PRNGKey(0)
key, subkey = jax.random.split(key)
r = jax.random.uniform(subkey)
この明示的な状態管理は、記述量を増やす一方で、分散環境における「再現性(Reproducibility)」を完全に制御することを可能にする 。どのデバイスで実行しても、同じキーからは必ず同じ乱数が生成されるため、デバッグや検証が極めて容易になる。
3.4 XLAによる最適化:オペレータ・フュージョンとメガカーネル
XLAコンパイラの最大の功績は「オペレータ・フュージョン(Operator Fusion)」である。GPUやTPUにおいて、処理時間の多くは演算そのものではなく、データをHBMから読み書きする時間に費やされる。XLAは、複数の演算(例:行列積 → バイアス加算 → ReLU → 残差接続)を解析し、それらを一つのカーネル(融合カーネル)に統合する。
これにより、中間結果をメモリに書き戻すことなく、レジスタやキャッシュ上で連続して処理を行うことが可能になる。いわゆる「メガカーネル(Megakernel)」の自動生成である 。手書きのCUDAカーネルによる最適化に近い性能を、Pythonコードから自動的に得られる点が、JAX/XLAスタックの最大の競争力と言える。
第4章 JAX AIスタック:モジュラーなエコシステムの全貌
JAX自体は「数値計算ライブラリ」であり、ニューラルネットワークの層やオプティマイザといった高レベルの機能を持たない。これらを補完し、完全なAI開発環境として機能させるのが、Googleが提唱する「JAX AI Stack」である。このスタックは、モノリシック(一枚岩)なフレームワークであるPyTorchやTensorFlowとは異なり、各コンポーネントが疎結合(Loosely Coupled)に設計されており、必要に応じて自由に組み合わせることができる 。
4.1 Flax: 状態管理の分離とモデル構築
Flaxは、JAX上でニューラルネットワークを構築するための標準的なライブラリである。JAXの純粋関数性と、開発者が慣れ親しんだオブジェクト指向プログラミングのギャップを埋める役割を果たす。
- Linen API: PyTorchの
nn.Moduleに似た記法を提供するが、内部的には状態を持たない。モデルのパラメータ(重み)はモデル定義の外にある辞書(Dictionary)として管理され、推論や学習のたびにapplyメソッドに明示的に渡される 。 - NNX (Experimental): より直感的な記述を可能にするため、Pythonの参照セマンティクスを活用した新しいAPI「NNX」も導入されつつある。これにより、PyTorchユーザーの移行障壁を大幅に下げることが期待されている 。
4.2 Optax: コンポーザブルな最適化
Optaxは、勾配降下法などの最適化アルゴリズムを提供するライブラリである。
- コンポーザビリティ: Optaxの最大の特徴は、オプティマイザを「勾配変換(Gradient Transformation)」の連鎖として定義できる点である。例えば、「AdamW」は「Scale By Adam」と「Add Decayed Weights」といった基本ブロックの組み合わせとして表現される。
- ステートレス設計: オプティマイザ自体も状態を持たず、更新されたオプティマイザ状態(モーメンタムなど)と更新されたパラメータを返す純粋関数として実装されている 。
4.3 インフラストラクチャ:OrbaxとGrain
数兆パラメータ規模のモデル学習を支えるのが、OrbaxとGrainである。
- Orbax: 超大規模なチェックポイント・ライブラリ。数千のTPUチップに分散されたモデルの状態を、非同期かつ高速にストレージへ保存・復元する機能を提供する。これにより、障害発生時のリカバリ時間を最小化する 。
- Grain: 大規模かつ決定論的(Deterministic)なデータローディング・ライブラリ。PythonのGIL(Global Interpreter Lock)を回避し、TPUの計算速度に追いつく高速なデータ供給を実現する。また、学習を中断・再開した際にも、データセットの全く同じ位置から、同じシャッフル順序で再開することを保証する 。
4.4 スタックの階層構造と「抽象化の連続体」
JAX AIスタックは、高レベルの抽象化から低レベルの制御までをシームレスにつなぐ「抽象化の連続体(Continuum of Abstraction)」を提供している 。
- アプリケーション層:
MaxText,MaxDiffusion,Gemma(学習済みモデルやリファレンス実装) - ライブラリ層:
Flax(モデル定義),Optax(最適化),Grain(データ) - コア変換層:
JAX(jit,grad,vmap,shard_map) - コンパイラ層:
XLA,StableHLO - ハードウェア層:
Cloud TPU,GPU
この構造において、開発者は通常ライブラリ層を利用するが、パフォーマンスの限界を追求する場合は、コンパイラ層をバイパスして直接ハードウェアを制御する「Pallas」のようなツール(後述)を利用することも可能である。
第5章 スケーリングの技術:SPMDと分散学習のパラダイム
TPUの真価は、単一チップではなく、数千チップが相互接続されたPodとして動作する際に発揮される。この大規模並列処理を支えるのが、SPMD(Single Program, Multiple Data)というパラダイムである。
5.1 SPMDとjax.sharding
従来の分散学習(Parameter Server方式など)では、コントローラが各ワーカーに個別の命令を送る複雑さがあった。対してSPMDでは、全てのチップが「全く同じプログラム」を実行するが、処理する「データ」が異なる。JAXにおいてこれは、巨大な配列(Tensor)を論理的なメッシュ(Device Mesh)上にどう分割(Shard)するかを定義するだけで実現できる 。
仮想デバイスメッシュの概念
例えば、8個のTPUコアを (2, 4) の2次元メッシュとして定義する。
mesh = jax.make_mesh((2, 4), ('data', 'model'))
このメッシュに対し、データのバッチ次元を data 軸に、モデルの隠れ層次元を model 軸に割り当てることで、データ並列(Data Parallelism)とモデル並列(Model Parallelism)を同時に、かつ直感的に記述できる。
5.2 自動並列化 vs 明示的シャーディング
JAXは並列化において3つのアプローチを提供する 。
- 自動並列化 (Auto-sharding):
コンパイラ(XLA/GSPMD)に全てを委ねる。開発者はシングルデバイス用のコードを書き、コンパイラが計算グラフを解析して、最適なデータの分割と通信(All-Reduceなど)を自動挿入する。手軽だが、意図しない分割が行われるリスクがある。 - 明示的シャーディング (Explicit Sharding):
NamedShardingやjax.jit(in_shardings=...)を用いて、ユーザーがデータの分割方法を型システムレベルで指定する。JAXは指定されたシャーディングを満たすように通信を挿入する。これが現在の主流かつ推奨される方法であり、予測可能性と制御性のバランスが取れている。 - 手動並列化 (
shard_map):pmap(後述)の進化形。デバイスごとのローカルな視点でコードを書き、明示的に通信集団演算(Collective Ops:psum,all_gatherなど)を記述する。FlashAttentionのような高度なアルゴリズムを実装する際に使用される。
5.3 pmapからshard_mapへの進化
JAXの初期には、並列化APIとして pmap (Parallel Map) が使われていた。これは配列の先頭次元をデバイス数にマッピングするシンプルなものであったが、柔軟性に欠けていた(例えば、デバイスメッシュの特定の軸だけでの通信や、ネストした並列化が困難だった)。
現在、Googleは pmap からshard_map への移行を推奨している。shard_map は、デバイスメッシュの任意の軸に対してマッピングが可能であり、より詳細な通信制御が可能である。これにより、最先端のLLM学習で必須となる Tensor Parallelism(テンソル並列)や Pipeline Parallelism(パイプライン並列)といった複雑な戦略も、JAX上で簡潔に記述できるようになった 。
5.4 FSDP(Fully Sharded Data Parallel)の実装
大規模モデル学習における事実上の標準技術であるFSDPも、JAXではエレガントに実装できる。FSDPは、モデルのパラメータ、勾配、オプティマイザ状態を全てのデバイスに分散させ、計算が必要な瞬間だけ通信を行ってパラメータを集める(All-Gather)手法である。
JAXでは、パラメータのシャーディング指定を PartitionSpec で記述するだけで、XLAコンパイラが自動的に必要な All-Gather と Reduce-Scatter を計算グラフに挿入する。ユーザーは複雑な通信コードを書く必要がない 。
第6章 Pallas:XLAの限界を超える「抜け道」
通常、XLAコンパイラは非常に効率的なコードを生成するが、極限のパフォーマンスが求められる特定のカーネル(例えば、TransformerのAttention機構におけるFlashAttentionや、特定の量子化カーネル)では、汎用コンパイラの最適化では不十分な場合がある。ここで登場するのがPallasである。
6.1 Pythonで書くカーネル言語
Pallasは、JAXの拡張機能であり、TPUやGPUのカーネルをPythonで直接記述することを可能にする。OpenAIのTriton言語に似たプログラミングモデルを採用しており、開発者は以下のような低レベルの制御を行うことができる 。
- メモリ階層の制御: TPUのHBM(グローバルメモリ)からVMEM(ベクターメモリ/SRAM)へのデータ転送を明示的に記述する。
- パイプライン処理: メモリロードと演算をオーバーラップさせる(パイプライン化する)ことで、レイテンシを隠蔽する。
- ブロック・プログラミング:
BlockSpecとGridを用いて、巨大な行列を小さなブロック(タイル)に分割し、シストリックアレイ上で効率的に処理するスケジュールを記述する 。
6.2 XLAとの共存
Pallasの強力な点は、JAXの通常のコードとシームレスに統合できることである。jax.jit でコンパイルされた関数の中から、pallas_call を使ってカスタムカーネルを呼び出すことができる。つまり、モデルの99%は高レベルなJAX/Flaxで記述し、ボトルネックとなる1%の処理だけをPallasで最適化するという「いいとこ取り」が可能である。これは、開発効率と実行性能の両立を迫られるAIエンジニアにとって強力な武器となる。
第7章 実践ガイド:Zero to TPU Training
理論的な解説に加え、実際にGoogle ColabやKaggleといった無料利用可能な環境を用いて、TPU上でJAX/Flaxによるモデル学習を行う手順を解説する。
特筆すべき点として、2025年1月現在、Google Colabの無料枠におけるTPUランタイムが更新され、従来のTPU v2が廃止され、より高性能なTPU v5e(一部情報ではv2-8の代替としてv5e-1)が利用可能になりつつある 。これは学習者にとって、最新世代のアーキテクチャに触れる絶好の機会である。
7.1 環境セットアップ
まず、JAXがTPUを正しく認識しているか確認する。Colabではランタイムのタイプを「TPU」に変更しておく。
import jax
import jax.numpy as jnp
# TPUデバイスの確認
# Colabでは自動的にTPUバックエンドが構成されるが、念のため確認
try:
print(f"JAX Backend: {jax.lib.xla_bridge.get_backend().platform}")
print(f"Available devices: {jax.devices()}")
print(f"Number of devices: {jax.device_count()}") # 通常は8
except RuntimeError:
print("TPU not found. Please check runtime settings.")
7.2 データローディング (TFDS & Grain)
JAX自体にはデータローダーが含まれていないため、TensorFlow Datasets (TFDS) を使用し、最終的にJAXが扱えるNumpy配列のイテレータに変換する手法が一般的である。
import tensorflow_datasets as tfds
import tensorflow as tf
def get_mnist_dataset(batch_size):
# TFDSでMNISTをロード
ds = tfds.load('mnist', split='train', as_supervised=True)
# 前処理:float32へのキャストと正規化
ds = ds.map(lambda x, y: (tf.cast(x, tf.float32) / 255.0, y))
# シャッフル、バッチ化、プリフェッチ
ds = ds.shuffle(1024).batch(batch_size).prefetch(tf.data.AUTOTUNE)
# tfds.as_numpyでJAX互換のイテレータに変換
return tfds.as_numpy(ds)
7.3 モデル定義 (Flax)
Flaxの nn.Module を使用してシンプルなCNNを定義する。@nn.compact デコレータを使用することで、__call__ メソッド内で層を定義・実行でき、コードが簡潔になる。
from flax import linen as nn
class CNN(nn.Module):
@nn.compact
def __call__(self, x):
x = nn.Conv(features=32, kernel_size=(3, 3))(x)
x = nn.relu(x)
x = nn.avg_pool(x, window_shape=(2, 2), strides=(2, 2))
x = x.reshape((x.shape[0], -1)) # Flatten
x = nn.Dense(features=256)(x)
x = nn.relu(x)
x = nn.Dense(features=10)(x)
return x
7.4 学習状態の管理 (TrainState)
Flaxでは、モデルのパラメータとオプティマイザの状態を TrainState というオブジェクトで一元管理する。
import optax
from flax.training import train_state
def create_train_state(rng, learning_rate):
model = CNN()
# パラメータの初期化(ダミー入力を使用)
params = model.init(rng, jnp.ones((1, 28, 28, 1)))['params']
# オプティマイザの定義
tx = optax.adam(learning_rate)
return train_state.TrainState.create(apply_fn=model.apply, params=params, tx=tx)
7.5 学習ステップ (Train Step) の実装と並列化
ここがJAXの核心部分である。train_step 関数を定義し、それを jax.jit でコンパイルする。さらに、データ並列化を実現するためにシャーディングを指定する。
from jax.sharding import Mesh, NamedSharding, PartitionSpec as P
# 1. デバイスメッシュの作成 (8個のTPUをデータ並列軸 'batch' に割り当て)
mesh = Mesh(jax.devices(), axis_names=('batch',))
# 2. 学習ステップ関数の定義とJITコンパイル
@jax.jit
def train_step(state, batch):
images, labels = batch
def loss_fn(params):
logits = state.apply_fn({'params': params}, images)
loss = optax.softmax_cross_entropy_with_integer_labels(logits, labels).mean()
return loss, logits
# jax.value_and_grad: 損失と勾配を同時に計算
(loss, logits), grads = jax.value_and_grad(loss_fn, has_aux=True)(state.params)
# パラメータの更新
state = state.apply_gradients(grads=grads)
return state, loss
# 3. 学習ループ
def train_epoch(state, train_ds):
# 入力データのシャーディング設定
# (Batch, Height, Width, Channel) のうち、Batch次元を分割
data_sharding = NamedSharding(mesh, P('batch', None, None, None))
for batch in train_ds:
# データをTPUメッシュへ転送・分散
batch = jax.device_put(batch, data_sharding)
state, loss = train_step(state, batch)
# ここでprint(loss)などを入れる場合、非同期実行に注意
return state
このコード例では、NamedSharding と jax.device_put を使用することで、データが自動的に8個のTPUコアに分散され、SPMD方式での並列学習が実行される。ユーザーは内部の通信コードを一切書く必要がない 。
第8章 戦略的示唆と将来展望
8.1 TCO(総所有コスト)の最適化
企業がJAX/TPUスタックを採用する最大の経済的動機は、圧倒的なコストパフォーマンスである。
- 推論コストの削減: TPU v5eは、v4と比較して推論時のドルあたり性能が2.5倍に向上している 。これは大規模サービスを運用する企業にとって、インフラコストの劇的な削減を意味する。
- メモリ帯域の価値: 最新のTPU v6e (Trillium) は、チップあたり1,600 GB/sという広帯域HBMを搭載している 。AIモデルの性能向上が計算速度(FLOPS)よりもメモリ転送速度に依存するようになる中、この帯域幅は「メモリの壁」を突破し、ハードウェアの稼働率(MFU: Model FLOPs Utilization)を高く維持するための重要な資産となる。
8.2 ベンダーロックインのリスクとOpenXLA
「TPUを使うとGoogle Cloudにロックインされるのではないか?」という懸念は、経営層やアーキテクトにとって重要な課題である。しかし、JAXスタック自体はハードウェア非依存であることを理解する必要がある。
- OpenXLAとStableHLO: Googleはコンパイラ基盤をオープンソース化しており、JAXで書かれたコードは NVIDIA GPU や AMD GPU 上でも、極めて高い効率で動作する。実際に、Apple や xAI、Anthropic といった他社も JAX を採用してモデル開発を行っているという事実は、このスタックのポータビリティを証明している 。
- 戦略的柔軟性: JAXを採用することは、特定のハードウェアへの依存ではなく、「コンパイラ最適化」という普遍的な技術への投資を意味する。これにより、将来的に TPU v7(Ironwood)が登場した際も、あるいは他社の新型チップが登場した際も、最小限の修正で最新ハードウェアの恩恵を受けることができる。
8.3 将来展望:Ironwoodとその先へ
Googleのロードマップによれば、2025年には第7世代TPU「Ironwood (v7)」の投入が計画されている。Ironwoodは、FP8演算へのネイティブ対応と、推論ワークロードへの更なる最適化が進むと予測されている 。また、JAXエコシステムにおいても、Pallasによるカーネル開発の民主化や、量子コンピューティング(Quantum Computing)との融合など、計算のフロンティアを拡張する試みが続いている。
結論
Google TPUとJAXは、もはやGoogle内部だけの秘伝の技術ではない。それは、ムーアの法則の鈍化とAIモデルの巨大化という二重の課題に対する、業界全体の標準的な解になりつつある。Pythonの柔軟性とスーパーコンピュータの性能を両立させるこのスタックを習得することは、AIエンジニアにとって、次の10年を生き抜くための最も強力な武器となるだろう。
Works cited
[1] TPU architecture | Google Cloud Documentation, accessed January 13, 2026, https://docs.cloud.google.com/tpu/docs/system-architecture-tpu-vm
[2] Why the JAX AI Stack is the New Standard for Megakernel Infrastructure - Rajat Pandit, accessed January 13, 2026, https://rajatpandit.com/business-case-for-jax/
[3] Google TPU Architecture: 7 Generations Explained | Introl Blog, accessed January 13, 2026, https://introl.com/blog/google-tpu-architecture-complete-guide-7-generations
[4] Tensor Processing Unit - Wikipedia, accessed January 13, 2026, https://en.wikipedia.org/wiki/Tensor_Processing_Unit
[5] Google TPUs Explained: Architecture & Performance for Gemini 3 | IntuitionLabs, accessed January 13, 2026, https://intuitionlabs.ai/articles/google-tpu-architecture-gemini-3
[6] How to Think About TPUs | How To Scale Your Model - GitHub Pages, accessed January 13, 2026, https://jax-ml.github.io/scaling-book/tpus/
[7] GPU and TPU Comparative Analysis Report | by ByteBridge - Medium, accessed January 13, 2026, https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a
[8] Tensor Processing Units (TPUs) - Google Cloud, accessed January 13, 2026, https://cloud.google.com/tpu
[9] TPU v5e - Google Cloud Documentation, accessed January 13, 2026, https://docs.cloud.google.com/tpu/docs/v5e
[10] TPU v6e - Google Cloud Documentation, accessed January 13, 2026, https://docs.cloud.google.com/tpu/docs/v6e
[11] Google Trillium TPU (v6e) introduction : r/LocalLLaMA - Reddit, accessed January 13, 2026, https://www.reddit.com/r/LocalLLaMA/comments/1gnru7c/google_trillium_tpu_v6e_introduction/
[12] JAX vs PyTorch: Comparing Two Deep Learning Frameworks - New Horizons, accessed January 13, 2026, https://www.newhorizons.com/resources/blog/jax-vs-pytorch-comparing-two-deep-learning-frameworks
[13] A guide to JAX for PyTorch developers | Google Cloud Blog, accessed January 13, 2026, https://cloud.google.com/blog/products/ai-machine-learning/guide-to-jax-for-pytorch-developers
[14] Deep Learning in Practice: A Technical Comparison of PyTorch and JAX - Medium, accessed January 13, 2026, https://medium.com/@nijesh-kanjinghat/deep-learning-in-practice-a-technical-comparison-of-pytorch-and-jax-6458a115dcde
[15] jax-ml/jax: Composable transformations of Python+NumPy programs: differentiate, vectorize, JIT to GPU/TPU, and more - GitHub, accessed January 13, 2026, https://github.com/jax-ml/jax
[16] Part 1: JAX neural net basics - JAX AI Stack, accessed January 13, 2026, https://docs.jaxstack.ai/en/latest/neural_net_basics.html
[17] Building production AI on Google Cloud TPUs with JAX, accessed January 13, 2026, https://developers.googleblog.com/building-production-ai-on-google-cloud-tpus-with-jax/
[18] Building production AI on Cloud TPUs with JAX, accessed January 13, 2026, https://docs.cloud.google.com/tpu/docs/jax-ai-stack
[19] Writing a Training Loop in JAX and Flax - Wandb, accessed January 13, 2026, https://wandb.ai/jax-series/simple-training-loop/reports/Writing-a-Training-Loop-in-JAX-and-Flax--VmlldzoyMzA4ODEy
[20] Image Classification with JAX, Flax, and Optax : A Step-by-Step Guide - Analytics Vidhya, accessed January 13, 2026, https://www.analyticsvidhya.com/blog/2024/11/image-classification-with-jax-flax-and-optax/
[21] MNIST Tutorial - Flax - Read the Docs, accessed January 13, 2026, https://flax.readthedocs.io/en/v0.8.2/experimental/nnx/mnist_tutorial.html
[22] Fine-tuning RecurrentGemma using JAX and Flax | Google AI for Developers, accessed January 13, 2026, https://ai.google.dev/gemma/docs/recurrentgemma/recurrentgemma_jax_finetune
[23] SPMD Parallelism with jax.shard_map and the Evolution Beyond pmap | CodeSignal Learn, accessed January 13, 2026, https://codesignal.com/learn/courses/advanced-jax-transformations-for-speed-scale/lessons/parallel-universes-spmd-parallelism-with-jaxshardmap-and-the-evolution-beyond-pmap
[24] Programming TPUs in JAX | How To Scale Your Model - GitHub Pages, accessed January 13, 2026, https://jax-ml.github.io/scaling-book/jax-stuff/
[25] What's the difference between xmap, shmap, pmap (pjit?) and which should I use? · jax-ml jax · Discussion #20312 - GitHub, accessed January 13, 2026, https://github.com/jax-ml/jax/discussions/20312
[26] jax.pmap - JAX documentation, accessed January 13, 2026, https://docs.jax.dev/en/latest/_autosummary/jax.pmap.html
[27] Manual parallelism with shard_map - JAX documentation, accessed January 13, 2026, https://docs.jax.dev/en/latest/notebooks/shard_map.html
[28] The Training Cookbook — JAX documentation, accessed January 13, 2026, https://docs.jax.dev/en/latest/the-training-cookbook.html
[29] Pallas Design - JAX documentation, accessed January 13, 2026, https://docs.jax.dev/en/latest/pallas/design/design.html
[30] Matrix Multiplication - JAX documentation, accessed January 13, 2026, https://docs.jax.dev/en/latest/pallas/tpu/matmul.html
[31] Colab - Google for Developers, accessed January 13, 2026, https://developers.google.com/colab/release-notes
[32] Issues · googlecolab/colabtools - GitHub, accessed January 13, 2026, https://github.com/googlecolab/colabtools/issues/result
[33] Train a GPT2 model with JAX on TPU for free - Google Developers ..., accessed January 13, 2026, https://developers.googleblog.com/train-gpt2-model-with-jax-on-tpu/
[34] MNIST tutorial - Flax - Read the Docs, accessed January 13, 2026, https://flax.readthedocs.io/en/stable/mnist_tutorial.html